python爬蟲調度器用法及實例代碼
我們一般使用爬蟲看到的都是最后的數據結果,對于整個的獲取過程沒有過多了解過。對于初學python的小伙伴們來說,不光是代碼的練習,還是原理的分析都是必不可少的。
小編把整個爬取的過程分為了幾個部分,從一開始的下載,到數據的去重解析,再到整個爬蟲循環的結束,以圖片和代碼的雙重形式展現給大家,希望能夠對爬蟲調度器有一個深刻的理解。
我們可以編寫幾個元件,每個元件完成一項功能,下圖中的藍底白字就是對這一流程的抽象:
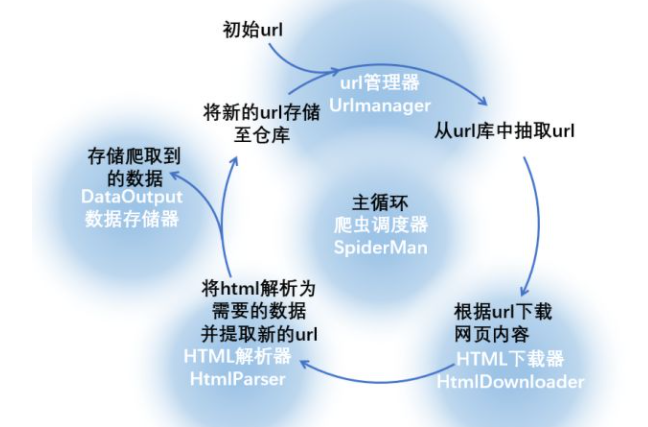
爬蟲調度器將要完成整個循環,下面寫出python下爬蟲調度器的程序:
# coding: utf-8new_urls = set()data = {}class SpiderMan(object): def __init__(self): #調度器內包含其它四個元件,在初始化調度器的時候也要建立四個元件對象的實例 self.manager = UrlManager() self.downloader = HtmlDownloader() self.parser = HtmlParser() self.output = DataOutput() def spider(self, origin_url): #添加初始url self.manager.add_new_url(origin_url) #下面進入主循環,暫定爬取頁面總數小于100 num = 0 while(self.manager.has_new_url() and self.manager.old_url_size()<100): try: num = num + 1 print '正在處理第{}個鏈接'.format(num) #從新url倉庫中獲取url new_url = self.manager.get_new_url() #調用html下載器下載頁面 html = self.downloader.download(new_url) #調用解析器解析頁面,返回新的url和data try: new_urls, data = self.parser.parser(new_url, html) except Exception, e: print e for url in new_urls: self.manager.add_new_url(url) #將已經爬取過的這個url添加至老url倉庫中 self.manager.add_old_url(new_url) #將返回的數據存儲至文件 self.output.store_data(data) print 'store data succefully' print '第{}個鏈接已經抓取完成'.format(self.manager.old_url_size()) except Exception, e: print e #爬取循環結束的時候將存儲的數據輸出至文件 self.output.output_html()
從整個循環的流程我們可以看出,由爬蟲調度器指揮四個元件完成數據的抓取、篩選、保存流程,并以此為基礎還可以進行新的循環。看懂原理之后,我們就可以使用以上的代碼進行實戰啦。
到此這篇關于python爬蟲調度器用法及實例代碼的文章就介紹到這了,更多相關python爬蟲調度器是什么內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:

 網公網安備
網公網安備