Django實現whoosh搜索引擎使用jieba分詞
本文介紹了Django實現whoosh搜索引擎使用jieba分詞,分享給大家,具體如下:
Django版本:3.0.4python包準備:
pip install django-haystackpip install jieba
使用jieba分詞
1.cd到site-packages內的haystack包,創建并編輯ChineseAnalyzer.py文件
# (注意:pip安裝的是django-haystack,但是實際包的文件夾名字為haystack)cd /usr/local/lib/python3.8/site-packages/haystack/backends/# 創建并編輯ChineseAnalyzer.py文件vim ChineseAnalyzer.py
2.修改ChineseAnalyzer.py文件內容
import jiebafrom whoosh.analysis import Tokenizer, Tokenclass ChineseTokenizer(Tokenizer): def __call__(self, value, positions=False, chars=False, keeporiginal=False, removestops=True, start_pos=0, start_char=0, mode=’’, **kwargs): t = Token(positions, chars, removestops=removestops, mode=mode,**kwargs) seglist = jieba.cut(value, cut_all=True) for w in seglist: t.original = t.text = w t.boost = 1.0 if positions: t.pos = start_pos + value.find(w) if chars: t.startchar = start_char + value.find(w) t.endchar = start_char + value.find(w) + len(w) yield tdef ChineseAnalyzer(): return ChineseTokenizer()
3.替換分詞器
cp whoosh_backend.py whoosh_cn_backend.pyvim whoosh_cn_backend.py
# 導入ChineseAnalyzer,并將原有的StemmingAnalyser替換為ChineseAnalyzerfrom .ChineseAnalyzer import ChineseAnalyzer# from whoosh.analysis import StemmingAnalyzer
vim替換命令: %s/StemmingAnalyzer/ChineseAnalyzer/g
4.修改setting.py文件
# 全文搜索框架配置HAYSTACK_CONNECTIONS = { ’default’: { # 使用whoosh引擎 # ’ENGINE’: ’haystack.backends.whoosh_backend.WhooshEngine’, # 使用jieba分詞 ’ENGINE’: ’haystack.backends.whoosh_cn_backend.WhooshEngine’, # 索引文件路徑 ’PATH’: os.path.join(BASE_DIR, ’whoosh_index’), },}
5.重新建立索引
python manage.py rebuild_index
可以看到,已經使用了jieba分詞。
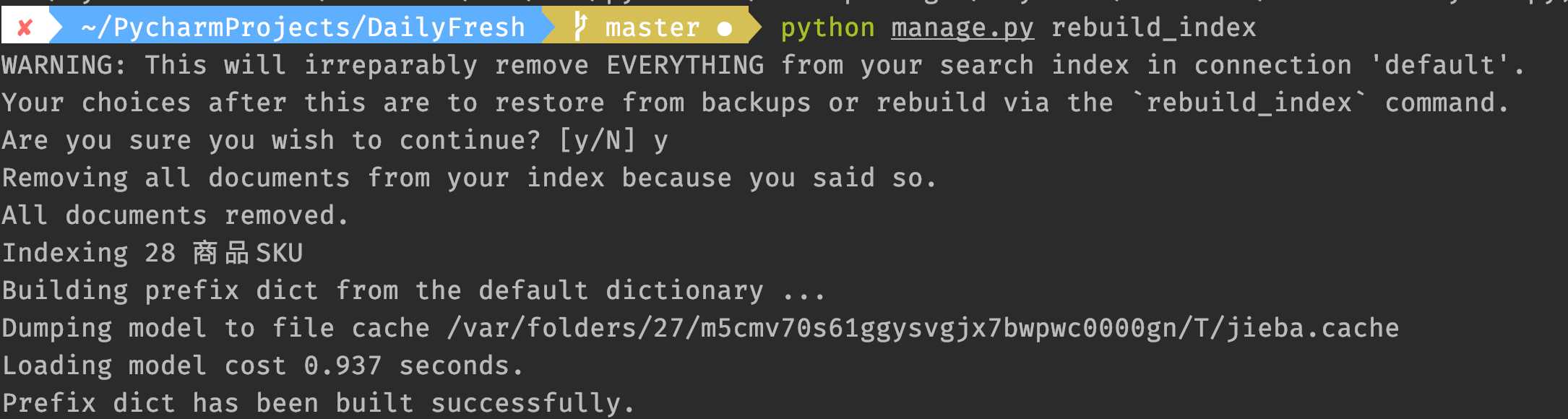
到此這篇關于Django實現whoosh搜索引擎使用jieba分詞的文章就介紹到這了,更多相關Django jieba分詞內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:
 網公網安備
網公網安備