Python用K-means聚類算法進(jìn)行客戶分群的實(shí)現(xiàn)
一、背景
1.項(xiàng)目描述
你擁有一個(gè)超市(Supermarket Mall)。通過會(huì)員卡,你用有一些關(guān)于你的客戶的基本數(shù)據(jù),如客戶ID,年齡,性別,年收入和消費(fèi)分?jǐn)?shù)。 消費(fèi)分?jǐn)?shù)是根據(jù)客戶行為和購買數(shù)據(jù)等定義的參數(shù)分配給客戶的。 問題陳述:你擁有這個(gè)商場(chǎng)。想要了解怎么樣的顧客可以很容易地聚集在一起(目標(biāo)顧客),以便可以給營(yíng)銷團(tuán)隊(duì)以靈感并相應(yīng)地計(jì)劃策略。2.數(shù)據(jù)描述
字段名 描述 CustomerID 客戶編號(hào) Gender 性別 Age 年齡 Annual Income (k$) 年收入,單位為千美元 Spending Score (1-100) 消費(fèi)分?jǐn)?shù),范圍在1~100
二、相關(guān)模塊
import numpy as npimport pandas as pd
from pandas import plottingimport matplotlib.pyplot as pltimport seaborn as snsimport plotly.graph_objs as goimport plotly.offline as py
from sklearn.cluster import KMeans
import warningswarnings.filterwarnings(’ignore’)
三、數(shù)據(jù)可視化
1.數(shù)據(jù)讀取
io = ’.../Mall_Customers.csv’df = pd.DataFrame(pd.read_csv(io))# 修改列名df.rename(columns={’Annual Income (k$)’: ’Annual Income’, ’Spending Score (1-100)’: ’Spending Score’}, inplace=True)print(df.head())print(df.describe())print(df.shape)print(df.count())print(df.dtypes)
輸出如下。
CustomerID Gender Age Annual Income Spending Score0 1 Male 19 15 391 2 Male 21 15 812 3 Female 20 16 63 4 Female 23 16 774 5 Female 31 17 40-----------------------------------------------------------------CustomerID Age Annual Income Spending Scorecount 200.000000 200.000000 200.000000 200.000000mean 100.500000 38.850000 60.560000 50.200000std 57.879185 13.969007 26.264721 25.823522min 1.000000 18.000000 15.000000 1.00000025% 50.750000 28.750000 41.500000 34.75000050% 100.500000 36.000000 61.500000 50.00000075% 150.250000 49.000000 78.000000 73.000000max 200.000000 70.000000 137.000000 99.000000-----------------------------------------------------------------(200, 5)CustomerID 200Gender 200Age 200Annual Income 200Spending Score 200dtype: int64-----------------------------------------------------------------CustomerID int64Gender objectAge int64Annual Income int64Spending Score int64dtype: object
2.數(shù)據(jù)可視化
2.1 平行坐標(biāo)圖
平行坐標(biāo)圖(Parallel coordinates plot)用于多元數(shù)據(jù)的可視化,將高維數(shù)據(jù)的各個(gè)屬性(變量)用一系列相互平行的坐標(biāo)軸表示, 縱向是屬性值,橫向是屬性類別。 若在某個(gè)屬性上相同顏色折線較為集中,不同顏色有一定的間距,則說明該屬性對(duì)于預(yù)標(biāo)簽類別判定有較大的幫助。 若某個(gè)屬性上線條混亂,顏色混雜,則可能該屬性對(duì)于標(biāo)簽類別判定沒有價(jià)值。plotting.parallel_coordinates(df.drop(’CustomerID’, axis=1), ’Gender’)plt.title(’平行坐標(biāo)圖’, fontsize=12)plt.grid(linestyle=’-.’)plt.show()
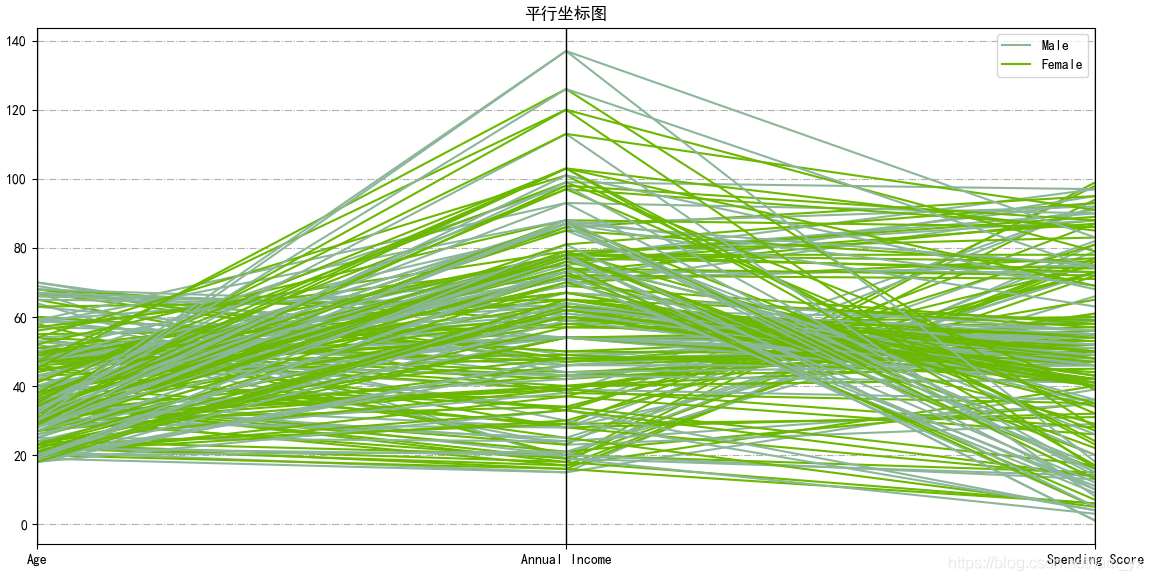
2.2 年齡/年收入/消費(fèi)分?jǐn)?shù)的分布
這里用了直方圖和核密度圖。(注:核密度圖看的是(x<X)的面積,而不是高度)
sns.set(palette='muted', color_codes=True) # seaborn樣式# 配置plt.rcParams[’axes.unicode_minus’] = False # 解決無法顯示符號(hào)的問題sns.set(font=’SimHei’, font_scale=0.8) # 解決Seaborn中文顯示問題# 繪圖plt.figure(1, figsize=(13, 6))n = 0for x in [’Age’, ’Annual Income’, ’Spending Score’]: n += 1 plt.subplot(1, 3, n) plt.subplots_adjust(hspace=0.5, wspace=0.5) sns.distplot(df[x], bins=16, kde=True) # kde 密度曲線 plt.title(’{}分布情況’.format(x)) plt.tight_layout()plt.show()
如下圖。從左到右分別是年齡、年收入和消費(fèi)能力的分布情況。發(fā)現(xiàn):
年齡方面:[30,36]范圍的客戶是最多的另外,在[20,21]也不少,但是60歲以上的老年人是最不常來消費(fèi)的。 年收入方面:大部分的客戶集中在[53,83]范圍里,在15以下和105以上的很少。 消費(fèi)分?jǐn)?shù)方面:消費(fèi)分?jǐn)?shù)在[40,55]的占了大多數(shù),在[70,80]范圍的次之。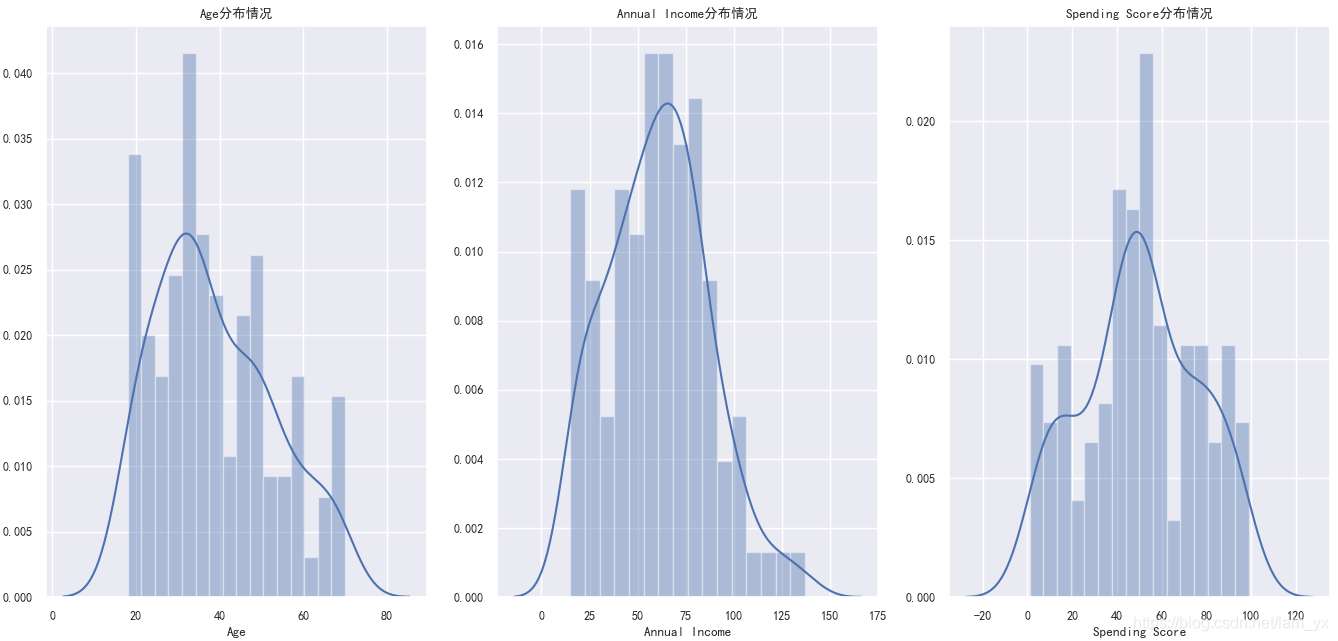
2.3年齡/年收入/消費(fèi)分?jǐn)?shù)的柱狀圖
這里使用的是柱狀圖,和直方圖不同的是:xxx軸上的每一個(gè)刻度對(duì)應(yīng)的是一個(gè)離散點(diǎn),而不是一個(gè)區(qū)間。
plt.figure(1, figsize=(13, 6))k = 0for x in [’Age’, ’Annual Income’, ’Spending Score’]: k += 1 plt.subplot(3, 1, k) plt.subplots_adjust(hspace=0.5, wspace=0.5) sns.countplot(df[x], palette=’rainbow’, alpha=0.8) plt.title(’{}分布情況’.format(x)) plt.tight_layout()plt.show()
如下圖。從上到下分別是年齡、年收入和消費(fèi)能力的柱狀圖。發(fā)現(xiàn):
年齡方面:[27,40]范圍的客戶居多。其中,32歲的客戶是商城的常客,55,、56、64、69歲的用戶卻很少。總的來說,年齡較大的人群較少,年齡較少的人群較多。 年收入方面:年收入在54和78的頻數(shù)是最多的。其他在各個(gè)收入的客戶頻數(shù)看起來相差不太大。 消費(fèi)分?jǐn)?shù)方面:消費(fèi)分?jǐn)?shù)在42的客戶數(shù)是最多的,56次之。有的客戶的分?jǐn)?shù)甚至達(dá)到了99,而分?jǐn)?shù)為1的客戶也存在,沒有分?jǐn)?shù)為0的客戶。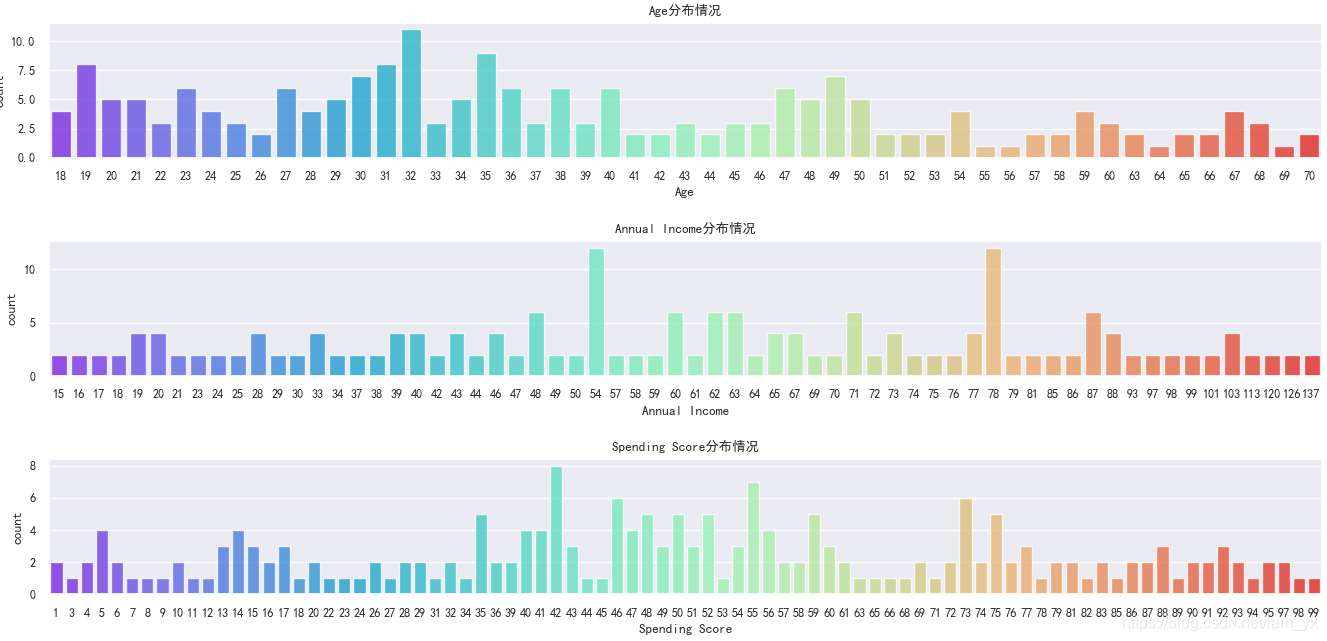
2.4不同性別用戶占比
df_gender_c = df[’Gender’].value_counts()p_lables = [’Female’, ’Male’]p_color = [’lightcoral’, ’lightskyblue’]p_explode = [0, 0.05]# 繪圖plt.pie(df_gender_c, labels=p_lables, colors=p_color, explode=p_explode, shadow=True, autopct=’%.2f%%’)plt.axis(’off’)plt.legend()plt.show()
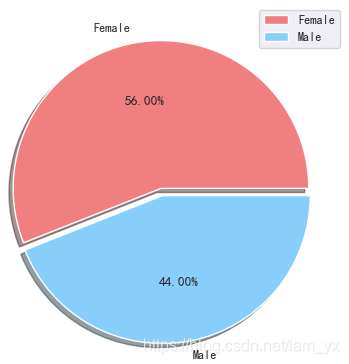
如下餅圖。女性以56%的份額居于領(lǐng)先地位,而男性則占整體的44%。特別是當(dāng)男性人口相對(duì)高于女性時(shí),這是一個(gè)比較大的差距。
2.5 兩兩特征之間的關(guān)系
# df_a_a_s = df.drop([’CustomerID’], axis=1)sns.pairplot(df, vars=[’Age’, ’Annual Income’, ’Spending Score’], hue=’Gender’, aspect=1.5, kind=’reg’)plt.show()
pairplot主要展現(xiàn)的是屬性(變量)兩兩之間的關(guān)系(線性或非線性,有無較為明顯的相關(guān)關(guān)系)。注意,我對(duì)男、女性的數(shù)據(jù)點(diǎn)進(jìn)行了區(qū)分(但是感覺數(shù)據(jù)在性別上的差異不大呀?)。如下組圖所示:
對(duì)角線上的圖是各個(gè)屬性的核密度分布圖。 非對(duì)角線的圖是兩個(gè)不同屬性之間的相關(guān)圖。看得出年收入和消費(fèi)能力之間有較為明顯的相關(guān)關(guān)系。 將 kind 參數(shù)設(shè)置為 reg 會(huì)為非對(duì)角線上的散點(diǎn)圖擬合出一條回歸直線,更直觀地顯示變量之間的關(guān)系。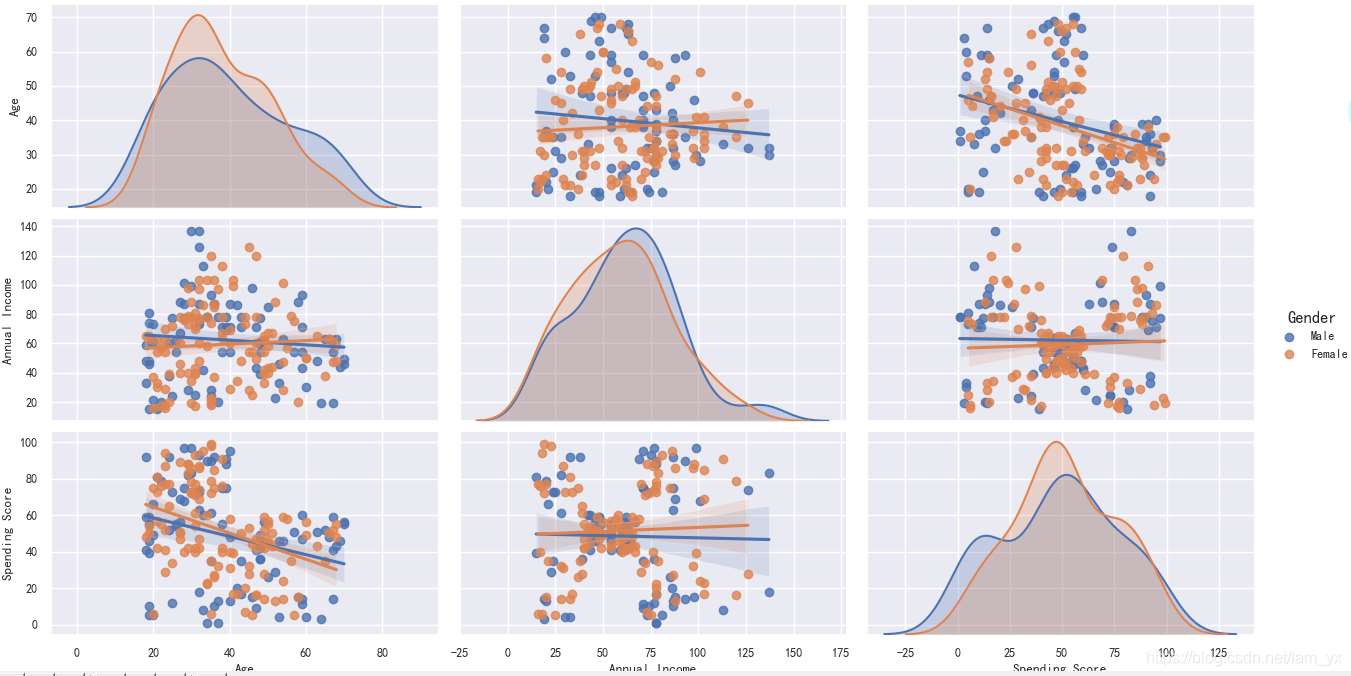
2.6 兩兩特征之間的分布
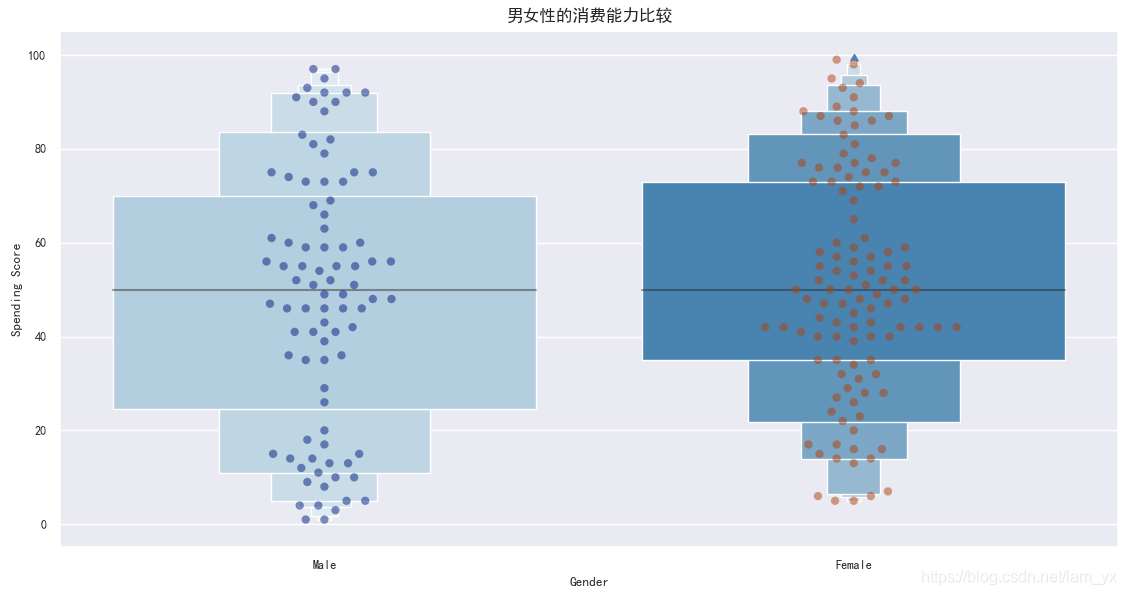
# 根據(jù)分類變量分組繪制一個(gè)縱向的增強(qiáng)箱型圖plt.rcParams[’axes.unicode_minus’] = False # 解決無法顯示符號(hào)的問題sns.set(font=’SimHei’, font_scale=0.8) # 解決Seaborn中文顯示問題sns.boxenplot(df[’Gender’], df[’Spending Score’], palette=’Blues’)# x:設(shè)置分組統(tǒng)計(jì)字段,y:數(shù)據(jù)分布統(tǒng)計(jì)字段sns.swarmplot(x=df[’Gender’], y=df[’Spending Score’], data=df, palette=’dark’, alpha=0.5, size=6)plt.title(’男女性的消費(fèi)能力比較’, fontsize=12)plt.show() 如下圖使用了增強(qiáng)箱圖,可以通過繪制更多的分位數(shù)來提供數(shù)據(jù)分布的信息,適用于大數(shù)據(jù)。 男性的消費(fèi)得分集中在[25,70],而女性的消費(fèi)得分集中在[35,75],一定程度上說明了女性在購物方面表現(xiàn)得比男性好。
# 根據(jù)分類變量分組繪制一個(gè)縱向的增強(qiáng)箱型圖plt.rcParams[’axes.unicode_minus’] = False # 解決無法顯示符號(hào)的問題sns.set(font=’SimHei’, font_scale=0.8) # 解決Seaborn中文顯示問題sns.boxenplot(df[’Gender’], df[’Spending Score’], palette=’Blues’)# x:設(shè)置分組統(tǒng)計(jì)字段,y:數(shù)據(jù)分布統(tǒng)計(jì)字段sns.swarmplot(x=df[’Gender’], y=df[’Spending Score’], data=df, palette=’dark’, alpha=0.5, size=6)plt.title(’男女性的消費(fèi)能力比較’, fontsize=12)plt.show()
其實(shí),下面這一部分也包含了上面的信息。
年齡方面:男性分布較為均勻,20多歲的比較多;女性的年齡大部分集中在20+~30+這個(gè)范圍,整體上較為年輕? 收入方面:男性略勝一籌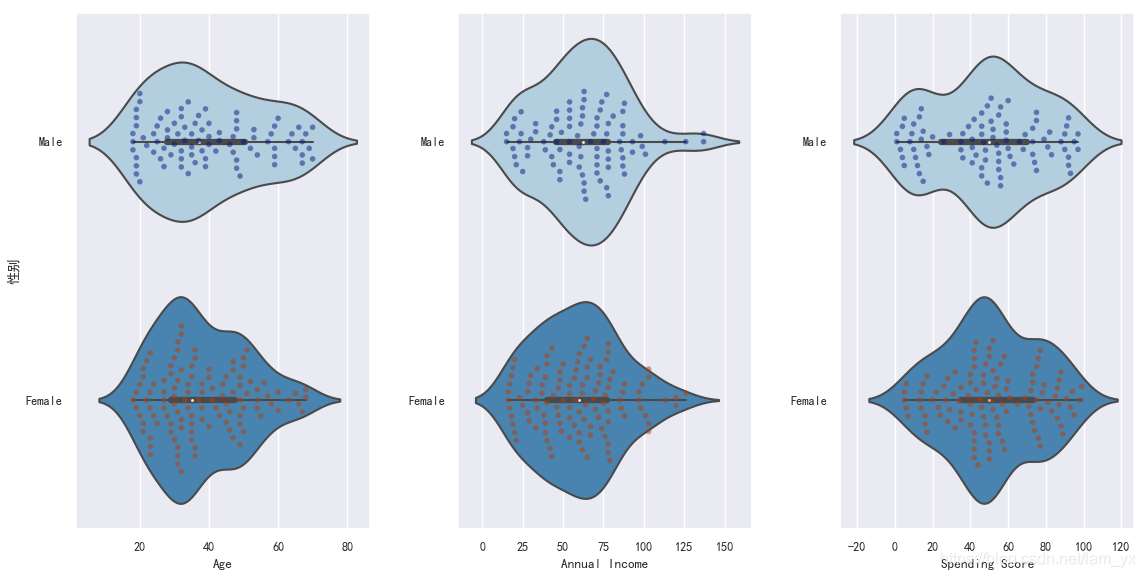
四、K-means聚類分析
0.手肘法簡(jiǎn)介
核心指標(biāo)
誤差平方和(sum of the squared errors,SSE)是所有樣本的聚類誤差反映了聚類效果的好壞,公式如下:

核心思想
隨著聚類數(shù)k 的增大,樣本劃分會(huì)更加精細(xì),每個(gè)簇的聚合程度會(huì)逐漸提高,那么SSE會(huì)逐漸變小。 當(dāng)k 小于真實(shí)聚類數(shù)時(shí),由于k 的增大會(huì)大幅增加每個(gè)簇的聚合程度,故SSE的下降幅度會(huì)很大。 當(dāng)k到達(dá)真實(shí)聚類數(shù)時(shí),再增加k所得到的聚合程度回報(bào)會(huì)迅速變小,所以SSE的下降幅度會(huì)驟減。然后隨著k值的繼續(xù)增大而趨于平緩,也就是說SSE和k的關(guān)系圖是一個(gè)手肘的形狀,而這個(gè)肘部對(duì)應(yīng)的k值就是數(shù)據(jù)的真實(shí)聚類數(shù)。1.基于年齡和消費(fèi)分?jǐn)?shù)的聚類
所需要的數(shù)據(jù)有‘Age’和‘Spending Score’。
df_a_sc = df[[’Age’, ’Spending Score’]].values# 存放每次聚類結(jié)果的誤差平方和inertia1 = []
使用手肘法確定最合適的kkk值。
for n in range(1, 11): # 構(gòu)造聚類器 km1 = (KMeans(n_clusters=n, # 要分成的簇?cái)?shù),int類型,默認(rèn)值為8 init=’k-means++’, # 初始化質(zhì)心,k-means++是一種生成初始質(zhì)心的算法 n_init=10, # 設(shè)置選擇質(zhì)心種子次數(shù),默認(rèn)為10次。返回質(zhì)心最好的一次結(jié)果(好是指計(jì)算時(shí)長(zhǎng)短) max_iter=300, # 每次迭代的最大次數(shù) tol=0.0001, # 容忍的最小誤差,當(dāng)誤差小于tol就會(huì)退出迭代 random_state=111, # 隨機(jī)生成器的種子 ,和初始化中心有關(guān) algorithm=’elkan’)) # ’full’是傳統(tǒng)的K-Means算法,’elkan’是采用elkan K-Means算法 # 用訓(xùn)練數(shù)據(jù)擬合聚類器模型 km1.fit(df_a_sc) # 獲取聚類標(biāo)簽 inertia1.append(km1.inertia_)
繪圖確定kkk值,這里將kkk確定為4。
plt.figure(1, figsize=(15, 6))plt.plot(np.arange(1, 11), inertia1, ’o’)plt.plot(np.arange(1, 11), inertia1, ’-’, alpha=0.7)plt.title(’手肘法圖’, fontsize=12)plt.xlabel(’聚類數(shù)’), plt.ylabel(’SSE’)plt.grid(linestyle=’-.’)plt.show()
通過如下圖,確定kkk=4。

確定kkk=4后。重新構(gòu)建kkk=4的K-means模型,并且繪制聚類圖。
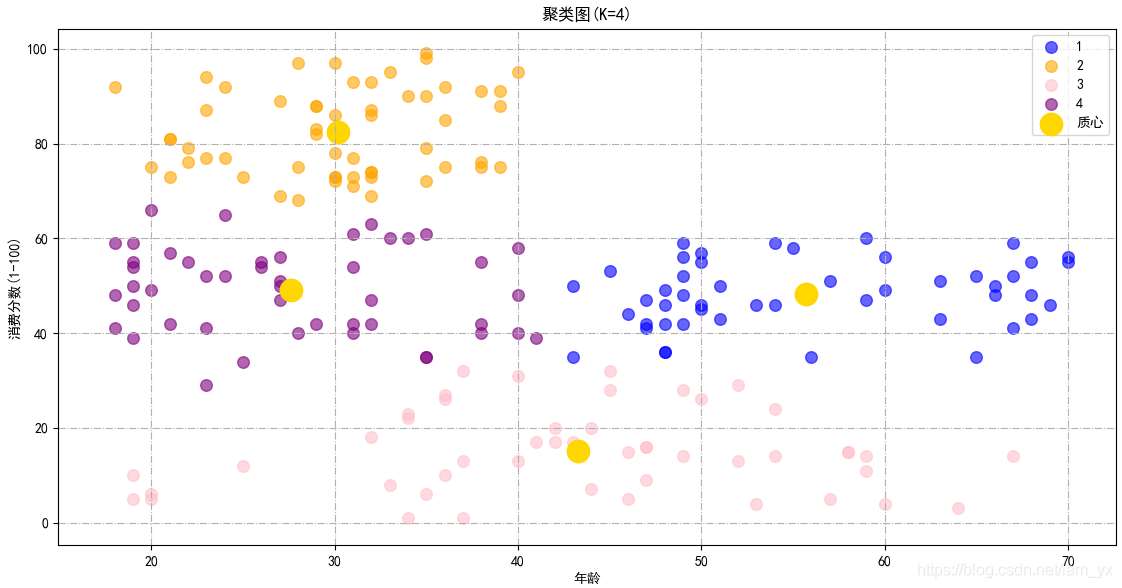
km1_result = (KMeans(n_clusters=4, init=’k-means++’, n_init=10, max_iter=300, tol=0.0001, random_state=111, algorithm=’elkan’))# 先fit()再predict(),一次性得到聚類預(yù)測(cè)之后的標(biāo)簽y1_means = km1_result.fit_predict(df_a_sc)# 繪制結(jié)果圖plt.scatter(df_a_sc[y1_means == 0][:, 0], df_a_sc[y1_means == 0][:, 1], s=70, c=’blue’, label=’1’, alpha=0.6)plt.scatter(df_a_sc[y1_means == 1][:, 0], df_a_sc[y1_means == 1][:, 1], s=70, c=’orange’, label=’2’, alpha=0.6)plt.scatter(df_a_sc[y1_means == 2][:, 0], df_a_sc[y1_means == 2][:, 1], s=70, c=’pink’, label=’3’, alpha=0.6)plt.scatter(df_a_sc[y1_means == 3][:, 0], df_a_sc[y1_means == 3][:, 1], s=70, c=’purple’, label=’4’, alpha=0.6)plt.scatter(km1_result.cluster_centers_[:, 0], km1_result.cluster_centers_[:, 1], s=260, c=’gold’, label=’質(zhì)心’)plt.title(’聚類圖(K=4)’, fontsize=12)plt.xlabel(’年收入(k$)’)plt.ylabel(’消費(fèi)分?jǐn)?shù)(1-100)’)plt.legend()plt.grid(linestyle=’-.’)plt.show()
效果如下,基于年齡和消費(fèi)能力這兩個(gè)參數(shù),可以將用戶劃分成4類。
2.基于年收入和消費(fèi)分?jǐn)?shù)的聚類
所需要的數(shù)據(jù)
df_ai_sc = df[[’Annual Income’, ’Spending Score’]].values# 存放每次聚類結(jié)果的誤差平方和inertia2 = []
同理,使用手肘法確定合適的kkk值。
for n in range(1, 11): # 構(gòu)造聚類器 km2 = (KMeans(n_clusters=n, init=’k-means++’, n_init=10, max_iter=300, tol=0.0001, random_state=111, algorithm=’elkan’)) # 用訓(xùn)練數(shù)據(jù)擬合聚類器模型 km2.fit(df_ai_sc) # 獲取聚類標(biāo)簽 inertia2.append(km2.inertia_)# 繪制手肘圖確定K值plt.figure(1, figsize=(15, 6))plt.plot(np.arange(1, 11), inertia1, ’o’)plt.plot(np.arange(1, 11), inertia1, ’-’, alpha=0.7)plt.title(’手肘法圖’, fontsize=12)plt.xlabel(’聚類數(shù)’), plt.ylabel(’SSE’)plt.grid(linestyle=’-.’)plt.show()
通過如下圖,確定kkk=5。
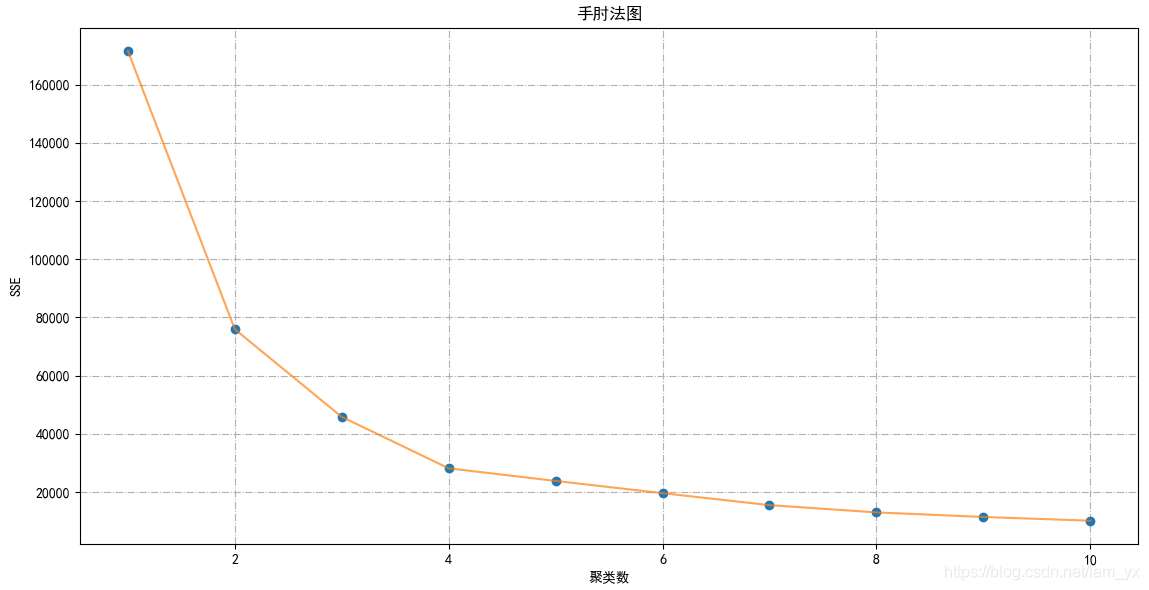
確定kkk=5后。重新構(gòu)建kkk=5的K-means模型,并且繪制聚類圖
km2_result = (KMeans(n_clusters=5, init=’k-means++’, n_init=10, max_iter=300, tol=0.0001, random_state=111, algorithm=’elkan’))# 先fit()再predict(),一次性得到聚類預(yù)測(cè)之后的標(biāo)簽y2_means = km2_result.fit_predict(df_ai_sc)# 繪制結(jié)果圖plt.scatter(df_ai_sc[y2_means == 0][:, 0], df_ai_sc[y2_means == 0][:, 1], s=70, c=’blue’, label=’1’, alpha=0.6)plt.scatter(df_ai_sc[y2_means == 1][:, 0], df_ai_sc[y2_means == 1][:, 1], s=70, c=’orange’, label=’2’, alpha=0.6)plt.scatter(df_ai_sc[y2_means == 2][:, 0], df_ai_sc[y2_means == 2][:, 1], s=70, c=’pink’, label=’3’, alpha=0.6)plt.scatter(df_ai_sc[y2_means == 3][:, 0], df_ai_sc[y2_means == 3][:, 1], s=70, c=’purple’, label=’4’, alpha=0.6)plt.scatter(df_ai_sc[y2_means == 4][:, 0], df_ai_sc[y2_means == 4][:, 1], s=70, c=’green’, label=’5’, alpha=0.6)plt.scatter(km2_result.cluster_centers_[:, 0], km2_result.cluster_centers_[:, 1], s=260, c=’gold’, label=’質(zhì)心’)plt.title(’聚類圖(K=5)’, fontsize=12)plt.xlabel(’年收入(k$)’)plt.ylabel(’消費(fèi)分?jǐn)?shù)(1-100)’)plt.legend()plt.grid(linestyle=’-.’)plt.show()
效果如下,基于年收入和消費(fèi)能力這兩個(gè)參數(shù),可以將用戶劃分成如下5類:
群體1 ⇒Rightarrow⇒目標(biāo)用戶:這類客戶年收入高,而且高消費(fèi)。 群體2 ⇒Rightarrow⇒普通用戶:年收入與消費(fèi)得分中等水平。 群體3 ⇒Rightarrow⇒高消費(fèi)用戶:年收入水平較低,但是卻有較強(qiáng)烈的消費(fèi)意愿,舍得花錢。 群體4 ⇒Rightarrow⇒節(jié)儉用戶:年收入高但是消費(fèi)意愿不強(qiáng)烈。群體5 ⇒Rightarrow⇒謹(jǐn)慎用戶:年收入和消費(fèi)意愿都較低。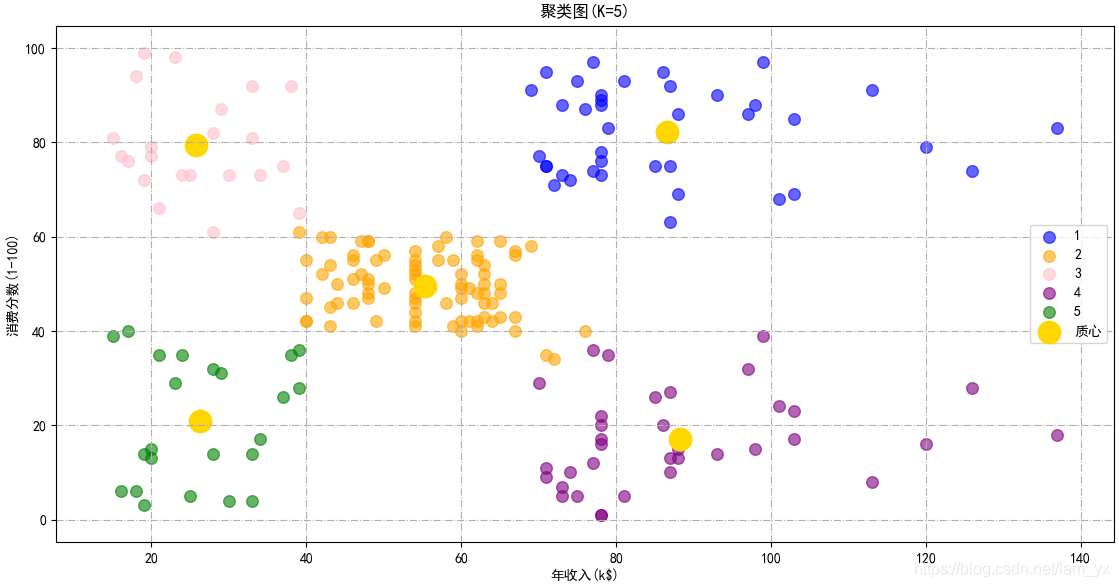
3.基于年齡、收入和消費(fèi)分?jǐn)?shù)的聚類所需要的數(shù)據(jù)
df_a_ai_sc = df[[’Age’, ’Annual Income’, ’Spending Score’]].values
聚類,kkk=5。
km3 = KMeans(n_clusters=5, init=’k-means++’, max_iter=300, n_init=10, random_state=0)km3.fit(df_a_ai_sc)
繪圖。
df[’labels’] = km3.labels_# 繪制3D圖trace1 = go.Scatter3d( x=df[’Age’], y=df[’Spending Score’], z=df[’Annual Income’], mode=’markers’, marker=dict( color=df[’labels’], size=10, line=dict( color=df[’labels’], width=12 ), opacity=0.8 ))df_3dfid = [trace1]layout = go.Layout( margin=dict( l=0, r=0, b=0, t=0 ), scene=dict( xaxis=dict(title=’年齡’), yaxis=dict(title=’消費(fèi)分?jǐn)?shù)(1-100)’), zaxis=dict(title=’年收入(k$)’) ))fig = go.Figure(data=df_3dfid, layout=layout)py.offline.plot(fig)
效果如下。
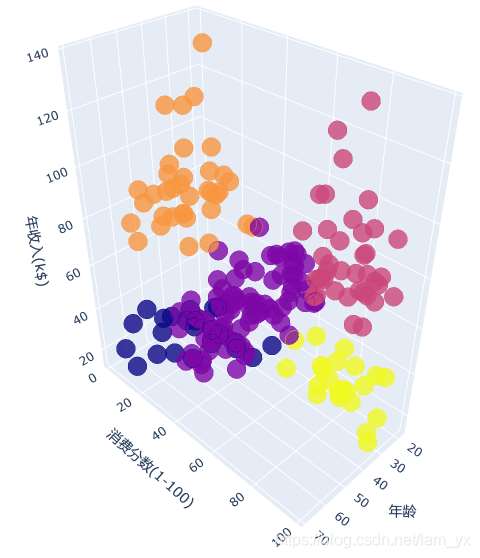
五、小結(jié)
主要是為了記錄下K-means學(xué)習(xí)過程,而且之前也參與了一個(gè)項(xiàng)目用到了K-means算法。 如何進(jìn)行特征旋是一個(gè)需要考慮的問題,我這里嘗試了三種不同的方案。然后,確定k 值是另一個(gè)重要的問題。我這個(gè)用了“手肘法”,但是可以配合“輪廓系數(shù)”綜合判斷。 還有許多地方不夠詳細(xì)。另外,如果有考慮不嚴(yán)謹(jǐn)?shù)牡胤剑瑲g迎批評(píng)指正!到此這篇關(guān)于Python用K-means聚類算法進(jìn)行客戶分群的實(shí)現(xiàn)的文章就介紹到這了,更多相關(guān)Python K-means客戶分群內(nèi)容請(qǐng)搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. Docker 容器健康檢查機(jī)制2. CSS3實(shí)現(xiàn)動(dòng)態(tài)翻牌效果 仿百度貼吧3D翻牌一次動(dòng)畫特效3. ASP.NET MVC使用正則表達(dá)式驗(yàn)證手機(jī)號(hào)碼4. php判斷一個(gè)請(qǐng)求是ajax請(qǐng)求還是普通請(qǐng)求的方法5. 基于python實(shí)現(xiàn)數(shù)組格式參數(shù)加密計(jì)算6. PHP接收json并將接收數(shù)據(jù)插入數(shù)據(jù)庫7. Rollup 簡(jiǎn)易入門示例教程8. Android View 事件防抖的兩種方案9. Python requests庫參數(shù)提交的注意事項(xiàng)總結(jié)10. python 爬取京東指定商品評(píng)論并進(jìn)行情感分析

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備