Python中免驗(yàn)證跳轉(zhuǎn)到內(nèi)容頁(yè)的實(shí)例代碼
相信很多人在瀏覽網(wǎng)頁(yè)時(shí),經(jīng)常會(huì)碰到需要輸入驗(yàn)證碼才可以繼續(xù)瀏覽的情況吧,遇到這種問(wèn)題,大多數(shù)人只能進(jìn)行繁瑣的注冊(cè)驗(yàn)證,今天小編教大家只要使用python就可以免驗(yàn)證方法。
以經(jīng)常用到的解答網(wǎng)站——上學(xué)吧為例,在網(wǎng)站里點(diǎn)擊答案頁(yè)面,會(huì)顯示驗(yàn)證后才可以查看提示,下面就使用python實(shí)現(xiàn)跳過(guò)驗(yàn)證碼。
我們需要通過(guò)python構(gòu)造隨機(jī)的 X-Forwarded-For 信息來(lái)繞過(guò) ASP 網(wǎng)站的 IP 檢測(cè),可以實(shí)現(xiàn)對(duì)輸入的網(wǎng)址正確性進(jìn)行檢查、對(duì)驗(yàn)證碼核驗(yàn)不通過(guò)時(shí)的處理等等。
python免驗(yàn)證跳轉(zhuǎn)頁(yè)面代碼如下:
# 繞過(guò)驗(yàn)證碼無(wú)限次獲取上學(xué)吧題目答案# 上學(xué)吧網(wǎng)址:https://www.shangxueba.com/askimport osimport randomimport requestsimport urllib3urllib3.disable_warnings() # 這句和上面一句是為了忽略 https 安全驗(yàn)證警告,參考:https://www.cnblogs.com/ljfight/p/9577783.htmlfrom bs4 import BeautifulSoupfrom PIL import Imagedef get_verifynum(session): # 網(wǎng)址的驗(yàn)證碼邏輯是先去這個(gè)網(wǎng)址獲取驗(yàn)證碼圖片,提交計(jì)算結(jié)果到另外一個(gè)網(wǎng)址進(jìn)行驗(yàn)證。r = session.get('https://www.shangxueba.com/ask/VerifyCode2.aspx', verify=False) # HTTPS 請(qǐng)求進(jìn)行 SSL 驗(yàn)證或忽略 SSL 驗(yàn)證才能請(qǐng)求成功,忽略方式為 verify=False。參考:https://www.cnblogs.com/ljfight/p/9577783.htmlwith open(’temp.png’,’wb+’) as f:f.write(r.content)image = Image.open(’temp.png’)image.show() # 調(diào)用系統(tǒng)的圖片查看軟件打開(kāi)驗(yàn)證碼圖片,如果不能打開(kāi),可以自己找到 temp.png 打開(kāi)。verifynum = input('n請(qǐng)輸入驗(yàn)證碼圖片中的計(jì)算結(jié)果:')image.close()os.remove('temp.png')return verifynumdef get_question(session):r = session.get(link)soup = BeautifulSoup(r.content, 'html.parser')description = soup.find(attrs={'name':'description'})[’content’] # 抓取題干內(nèi)容return descriptiondef get_answer(session, verifynum, dataid):data1 = {'Verify': verifynum,'action': 'CheckVerify',}session.post('https://www.shangxueba.com/ask/ajax/GetZuiJia.aspx', data=data1) # 核查驗(yàn)證碼正確性data2 = {'phone':'','dataid': dataid,'action': 'submitVerify','siteid': '1001','Verify': verifynum,}r = session.post('https://www.shangxueba.com/ask/ajax/GetZuiJia.aspx', data=data2)soup = BeautifulSoup(r.content, 'html.parser')ans = soup.find(’h6’)print('n' + ’-’*45)if(ans): # 只有驗(yàn)證碼核查通過(guò)才會(huì)顯示答案print('n題目:' + get_question(session))print(ans.text)else:print(’n沒(méi)有找到答案!請(qǐng)檢查驗(yàn)證碼或網(wǎng)址是否輸入有誤!n’)print(’-’*45)if __name__ == ’__main__’:s = requests.session()while True:s.headers.update({'X-Forwarded-For':'%d.%d.%d.%d'%(random.randint(120,125),random.randint(1,200),random.randint(1,200),random.randint(1,200))}) # 這一句是整個(gè)程序的關(guān)鍵,通過(guò)修改 X-Forwarded-For 信息來(lái)欺騙 ASP 站點(diǎn)對(duì)于 IP 的驗(yàn)證。link = input('n請(qǐng)輸入上學(xué)吧網(wǎng)站上某道題目的網(wǎng)址,例如:https://www.shangxueba.com/ask/8952241.htmlnn請(qǐng)輸入:').strip() # 過(guò)濾首尾的空格if(link[0:31] != 'https://www.shangxueba.com/ask/' or link[-4:] != 'html'):print('n網(wǎng)址輸入有誤!請(qǐng)重新輸入!n')continuedataid = link.split('/')[-1].replace(r'.html','') # 提取網(wǎng)址最后的數(shù)字部分if(dataid.isdigit()): # 根據(jù)格式,dataid 應(yīng)該全部為數(shù)字,判斷字符串是否全部為數(shù)字,返回 True 或者 Falseverifynum = get_verifynum(s)get_answer(s, verifynum, dataid)else:print('n網(wǎng)址輸入有誤!請(qǐng)重新輸入!n')continue
注意:其中 requests 和 beautifulsoup 兩個(gè)庫(kù)需要另外安裝,建議使用 pip 方式安裝:
pip install requestspip install beautifulsoup4
Python 腳本運(yùn)行流程:
首先復(fù)制上學(xué)吧某道題目的網(wǎng)址,類(lèi)似以下格式:
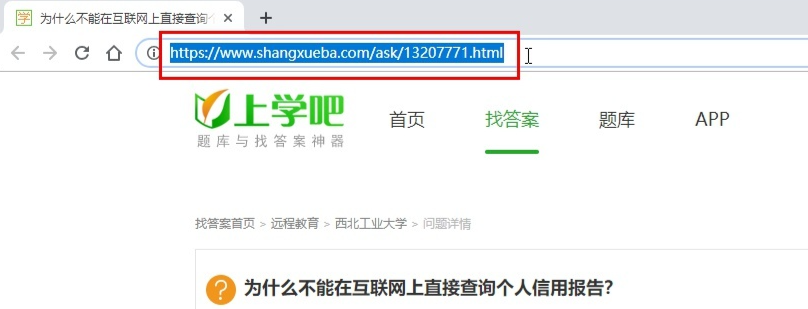
然后運(yùn)行python腳本,復(fù)制粘貼網(wǎng)址。

按Enter鍵,自動(dòng)下載驗(yàn)證碼圖片存為 temp.png,然后自動(dòng)讀取圖片并展示,也可以手動(dòng)打開(kāi)同目錄下的 temp.png 圖片。
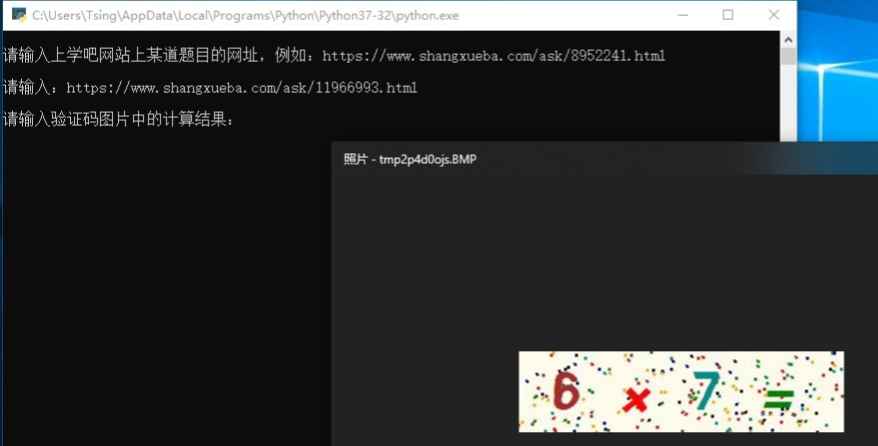
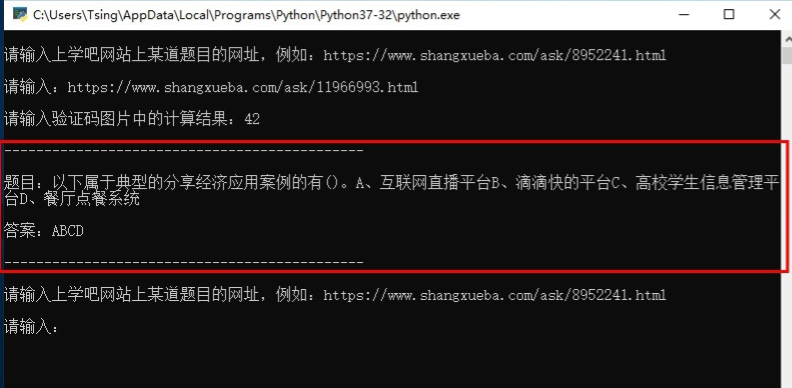
最后在命令行窗口輸入驗(yàn)證碼圖片中的計(jì)算結(jié)果即可獲取題目詳情以及正確答案。
到此這篇關(guān)于Python中免驗(yàn)證跳轉(zhuǎn)到內(nèi)容頁(yè)的實(shí)例代碼的文章就介紹到這了,更多相關(guān)Python如何免驗(yàn)證跳轉(zhuǎn)到內(nèi)容頁(yè)內(nèi)容請(qǐng)搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. asp畫(huà)中畫(huà)廣告插入在每篇文章中的實(shí)現(xiàn)方法2. 讓chatgpt將html中的圖片轉(zhuǎn)為base64方法示例3. 使用純HTML的通用數(shù)據(jù)管理和服務(wù)4. ASP編碼必備的8條原則5. asp中Request.ServerVariables的參數(shù)集合6. WMLScript腳本程序設(shè)計(jì)第1/9頁(yè)7. CSS Hack大全-教你如何區(qū)分出IE6-IE10、FireFox、Chrome、Opera8. Thinkphp3.2.3反序列化漏洞實(shí)例分析9. PHP session反序列化漏洞深入探究10. 熊海CMS代碼審計(jì)漏洞分析

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備