python反爬蟲方法的優(yōu)缺點(diǎn)分析
我們選擇一種問題的解決辦法,通常需要考慮到想要達(dá)到的效果,還有最重要的是這個辦法本身的優(yōu)缺點(diǎn)有哪些,與其他的方法對比哪一個更好。之前小編之前也教過大家在python應(yīng)對反爬蟲的方法,那么小伙伴們知道具體情況下選擇哪一種辦法更適合嗎?今天就其中的user-agent和ip代碼兩個辦法進(jìn)行優(yōu)缺點(diǎn)分析比較,讓大家可以明確不同辦法的區(qū)別從而進(jìn)行選擇。
方法一:
可以自己設(shè)置一下user-agent,或者更好的是,可以從一系列的user-agent里隨機(jī)挑出一個符合標(biāo)準(zhǔn)的使用。
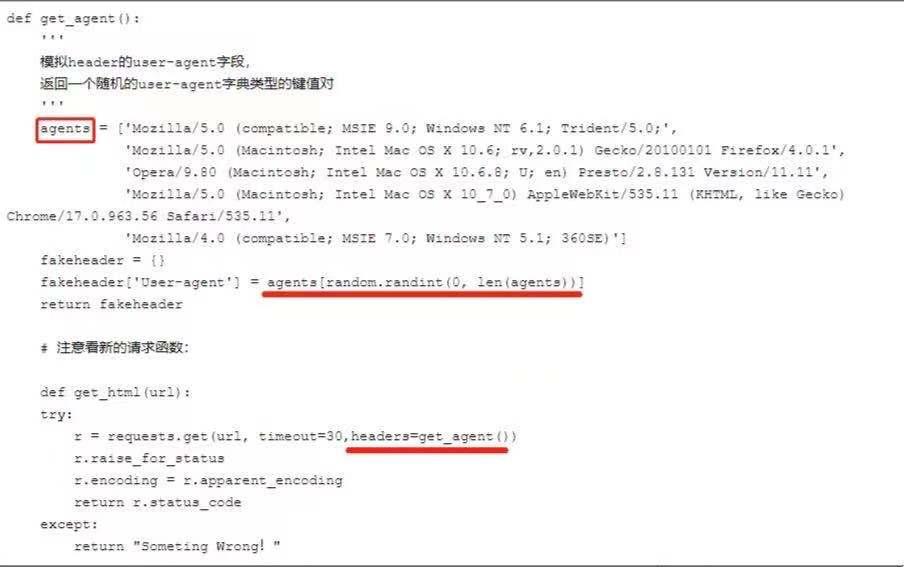 缺點(diǎn):
缺點(diǎn):
容易偽造頭部,github上有人分享開源庫fake-useragent
IP限制
如果一個固定的ip在短暫的時間內(nèi),快速大量的訪問一個網(wǎng)站,后臺管理員可以編寫IP限制,不讓該IP繼續(xù)訪問。
方法二:
比較成熟的方式是:IP代理池
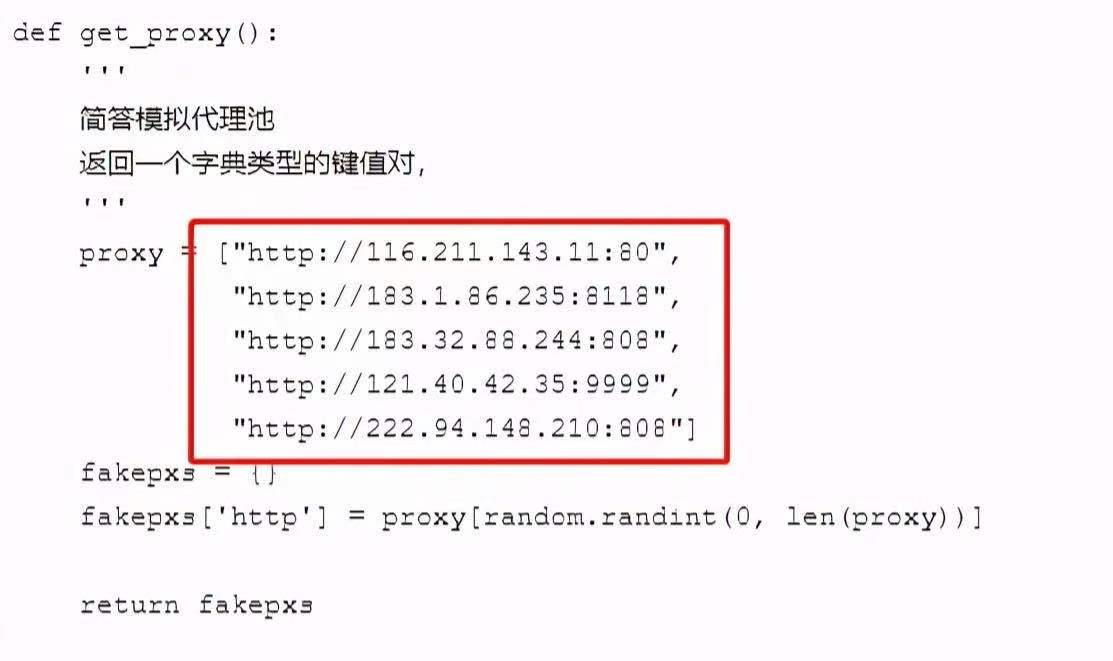
簡單的說,就是通過ip代理,從不同的ip進(jìn)行訪問,這樣就不會被封掉ip了。
可是ip代理的獲取本身就是一個很麻煩的事情,網(wǎng)上有免費(fèi)和付費(fèi)的,但是質(zhì)量都層次不齊。如果是企業(yè)里需要的話,可以通過自己購買集群云服務(wù)來自建代理池。
缺點(diǎn):
可以使用免費(fèi)/付費(fèi)代理,繞過檢測。
讀完本篇我們會發(fā)現(xiàn),每種方法都有它的缺陷,我們要做的就是發(fā)揮使用它的優(yōu)勢出。根據(jù)不同的環(huán)境情況,可以選擇適合自己操作順手的方法。對于兩種方法知識點(diǎn)遺忘的,可以直接點(diǎn)擊進(jìn)去進(jìn)行回顧。
到此這篇關(guān)于python反爬蟲方法的優(yōu)缺點(diǎn)分析的文章就介紹到這了,更多相關(guān)python解決反爬蟲方法的優(yōu)缺點(diǎn)對比內(nèi)容請搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. html5手機(jī)觸屏touch事件介紹2. 怎樣打開XML文件?xml文件如何打開?3. 微信公眾號可通過現(xiàn)金紅包接口發(fā)放微信支付現(xiàn)金紅包(附開發(fā)教程)4. Vue+elementUI下拉框自定義顏色選擇器方式5. xml文件的結(jié)構(gòu)解讀第1/2頁6. CSS3實(shí)例分享之多重背景的實(shí)現(xiàn)(Multiple backgrounds)7. 如何使用CSS3畫出一個叮當(dāng)貓8. HTML基礎(chǔ)知識總結(jié)9. 讓 Asp 與 XML 交互10. 如何學(xué)習(xí)html的各種標(biāo)簽

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備