python爬蟲(chóng)利器之requests庫(kù)的用法(超全面的爬取網(wǎng)頁(yè)案例)
利用pip安裝:pip install requests
基本請(qǐng)求
req = requests.get('https://www.baidu.com/')req = requests.post('https://www.baidu.com/')req = requests.put('https://www.baidu.com/')req = requests.delete('https://www.baidu.com/')req = requests.head('https://www.baidu.com/')req = requests.options(https://www.baidu.com/)1.get請(qǐng)求
參數(shù)是字典,我們可以傳遞json類(lèi)型的參數(shù):
import requestsfrom fake_useragent import UserAgent#請(qǐng)求頭部庫(kù)headers = {'User-Agent':UserAgent().random}#獲取一個(gè)隨機(jī)的請(qǐng)求頭url = 'https://www.baidu.com/s'#網(wǎng)址params={ 'wd':'豆瓣' #網(wǎng)址的后綴}requests.get(url,headers=headers,params=params)
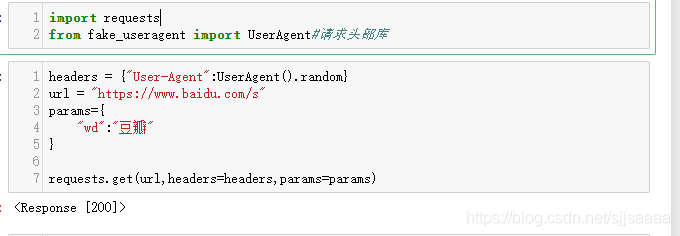
返回了狀態(tài)碼,所以我們要想獲取內(nèi)容,需要將其轉(zhuǎn)成text:
#get請(qǐng)求headers = {'User-Agent':UserAgent().random}url = 'https://www.baidu.com/s'params={ 'wd':'豆瓣'}response = requests.get(url,headers=headers,params=params)response.text2.post 請(qǐng)求
參數(shù)也是字典,也可以傳遞json類(lèi)型的參數(shù):
import requests from fake_useragent import UserAgentheaders = {'User-Agent':UserAgent().random}url = 'https://www.baidu.cn/index/login/login' #登錄賬號(hào)密碼的網(wǎng)址params = { 'user':'1351351335',#賬號(hào) 'password':'123456'#密碼}response = requests.post(url,headers=headers,data=params)response.text
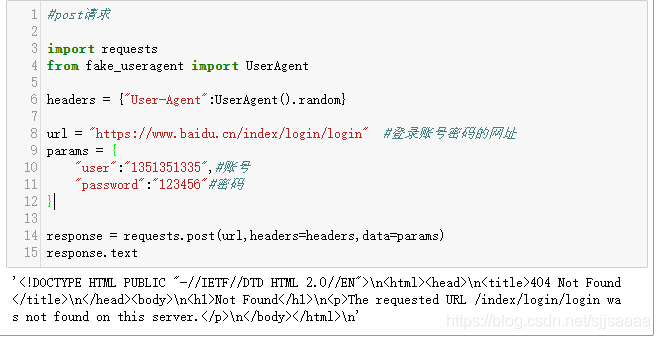
因?yàn)檫@里需要一個(gè)登錄的網(wǎng)頁(yè),我這里就隨便用了一個(gè),沒(méi)有登錄,所以顯示的結(jié)果是這樣的,如果想要測(cè)試登錄的效果,請(qǐng)找一個(gè)登錄的頁(yè)面去嘗試一下。
3.IP代理采集時(shí)為避免被封IP,經(jīng)常會(huì)使用代理,requests也有相應(yīng) 的proxies屬性。
#IP代理import requests from fake_useragent import UserAgentheaders = {'User-Agent':UserAgent().random}url = 'http://httpbin.org/get' #返回當(dāng)前IP的網(wǎng)址proxies = { 'http':'http://yonghuming:123456@192.168.1.1:8088'#http://用戶名:密碼@IP:端口號(hào) #'http':'https://182.145.31.211:4224'# 或者IP:端口號(hào)}requests.get(url,headers=headers,proxies=proxies)
代理IP可以去:快代理去找,也可以去購(gòu)買(mǎi)。http://httpbin.org/get。這個(gè)網(wǎng)址是查看你現(xiàn)在的信息:

可以通過(guò)timeout屬性設(shè)置超時(shí)時(shí)間,一旦超過(guò)這個(gè)時(shí)間還沒(méi)獲取到響應(yīng)內(nèi)容,就會(huì)提示錯(cuò)誤。
#設(shè)置訪問(wèn)時(shí)間requests.get('http://baidu.com/',timeout=0.1)

ssl驗(yàn)證。
import requests from fake_useragent import UserAgent #請(qǐng)求頭部庫(kù)url = 'https://www.12306.cn/index/' #需要證書(shū)的網(wǎng)頁(yè)地址headers = {'User-Agent':UserAgent().random}#獲取一個(gè)隨機(jī)請(qǐng)求頭requests.packages.urllib3.disable_warnings()#禁用安全警告response = requests.get(url,verify=False,headers=headers)response.encoding = 'utf-8' #用來(lái)顯示中文,進(jìn)行轉(zhuǎn)碼response.text

import requestsfrom fake_useragent import UserAgentheaders = {'User-Agent':UserAgent().chrome}login_url = 'https://www.baidu.cn/index/login/login' #需要登錄的網(wǎng)頁(yè)地址params = { 'user':'yonghuming',#用戶名 'password':'123456'#密碼}session = requests.Session() #用來(lái)保存cookie#直接用session 歹意requests response = session.post(login_url,headers=headers,data=params)info_url = 'https://www.baidu.cn/index/user.html' #登錄完賬號(hào)密碼以后的網(wǎng)頁(yè)地址resp = session.get(info_url,headers=headers)resp.text
因?yàn)槲疫@里沒(méi)有使用需要賬號(hào)密碼的網(wǎng)頁(yè),所以顯示這樣:

我獲取了一個(gè)智慧樹(shù)的網(wǎng)頁(yè)
#cookie import requestsfrom fake_useragent import UserAgentheaders = {'User-Agent':UserAgent().chrome}login_url = 'https://passport.zhihuishu.com/login?service=https://onlineservice.zhihuishu.com/login/gologin' #需要登錄的網(wǎng)頁(yè)地址params = { 'user':'12121212',#用戶名 'password':'123456'#密碼}session = requests.Session() #用來(lái)保存cookie#直接用session 歹意requests response = session.post(login_url,headers=headers,data=params)info_url = 'https://onlne5.zhhuishu.com/onlinWeb.html#/stdetInex' #登錄完賬號(hào)密碼以后的網(wǎng)頁(yè)地址resp = session.get(info_url,headers=headers)resp.encoding = 'utf-8'resp.text

代碼 含義 resp.json() 獲取響應(yīng)內(nèi)容 (以json字符串) resp.text 獲取相應(yīng)內(nèi)容(以字符串) resp.content 獲取響應(yīng)內(nèi)容(以字節(jié)的方式) resp.headers 獲取響應(yīng)頭內(nèi)容 resp.url 獲取訪問(wèn)地址 resp.encoding 獲取網(wǎng)頁(yè)編碼 resp.request.headers 請(qǐng)求頭內(nèi)容 resp.cookie 獲取cookie
到此這篇關(guān)于python爬蟲(chóng)利器之requests庫(kù)的用法(超全面的爬取網(wǎng)頁(yè)案例)的文章就介紹到這了,更多相關(guān)python爬蟲(chóng)requests庫(kù)用法內(nèi)容請(qǐng)搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. ASP中解決“對(duì)象關(guān)閉時(shí),不允許操作。”的詭異問(wèn)題……2. msxml3.dll 錯(cuò)誤 800c0019 系統(tǒng)錯(cuò)誤:-2146697191解決方法3. 得到XML文檔大小的方法4. ASP使用MySQL數(shù)據(jù)庫(kù)的方法5. WMLScript的語(yǔ)法基礎(chǔ)6. ASP動(dòng)態(tài)網(wǎng)頁(yè)制作技術(shù)經(jīng)驗(yàn)分享7. xml中的空格之完全解說(shuō)8. html小技巧之td,div標(biāo)簽里內(nèi)容不換行9. XML入門(mén)的常見(jiàn)問(wèn)題(四)10. ASP中if語(yǔ)句、select 、while循環(huán)的使用方法
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備