文章詳情頁
網頁爬蟲 - Python:爬蟲的中文編碼問題?
瀏覽:177日期:2022-08-26 10:56:16
問題描述
爬取中文網頁后正則匹配出中文,得打UTF-8的編碼字符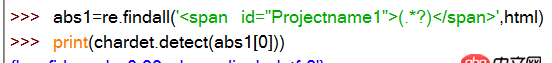
將其輸出為.csv文件
在.CSV中顯示為亂碼
用記事本打開.csv又可以正常顯示為中文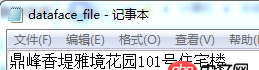
有沒有大神指點是怎么一回事?怎樣才能在Excel里直接看到中文?
問題解答
回答1:簡單地方法是用pandas的to_excel方法轉化成.xlsx文件,因為.xlsx默認編碼是默認支持Excel的,區別當然是無法用記事本打開。
import pandas as pda = pd.read_csv(’./test.csv’)a.to_excel(’./test_output.xlsx’, index=False)a.to_excel(’./test_output.csv’, index=False)
我這里沒有windows可以測試,可以嘗試寫入編碼為gb2312或者gbk試試。
表格文件類I/O的話其實pandas更方便一點。
回答2:abs1=abs1.decode().encode(’gbk’)
回答3:excel默認使用的是GBK編碼。
回答4:新建一個excel文件,然后點 數據 自文本,導入csv文件
相關文章:
1. java - Spring Mvc全局異常處理器@ControllerAdvice不起作用?2. html - 移動端radio無法選中3. javascript - 關于禁用文本選擇與復制的問題4. Java中call by value和call by reference的區別5. 前端 - html5 audio不能播放6. node.js - 在vuejs-templates/webpack中dev-server.js里為什么要exports readyPromise?7. css - 關于偽類背景問題8. css3 - transition屬性當鼠標一開的時候設置的時間不起作用9. html5 - 如何實現圖中的刻度漸變效果?10. CSS3 border凹陷該如何編寫?
排行榜

 網公網安備
網公網安備